Development of AI and MT ---- SMT
StatisticalMachine Translation (SMT)
In July 1993, at the Fourth Machine Translation Summit (MT Summit IV) held in Kobe, Japan, British scholar J. Hutchins pointed out in his keynote speech that since 1989, machine translation had entered a new era. This new era was marked by the introduction of corpus-based methods into rule-based machine translation technologies, including statistical methods, example-based methods, and methods for converting corpora into language knowledge bases through corpus processing. These methods can acquire linguistic knowledge from large-scale real-text corpora, rather than relying solely on the subjective intuition of linguists or the rules found in grammar books, fundamentally changing the way linguistic knowledge is obtained for machine translation. This approach, based on the processing of large-scale real texts, propelled the strategic shift in machine translation, leading it to a new stage where rule-based machine translation evolved into statistical machine translation (SMT).
As the strategic shift progressed, corpus-based methods permeated all aspects of machine translation research, leading to the establishment of numerous corpus-based statistical machine translation systems. To address the common issue of data sparsity in statistical machine translation, some systems cleverly combined corpus-based probabilistic statistical methods with rule-based logical reasoning methods, achieving notable success.
In 2000, at the summer workshop on machine translation at Johns Hopkins University, researchers from institutions such as the University of Southern California, the University of Rochester, Johns Hopkins University, Xerox Corporation, the University of Pennsylvania, and Stanford University discussed statistical machine translation. Led by young doctoral student Franz Josef Och, 13 scientists wrote a summary report titled "Syntax for Statistical Machine Translation." This report proposed effective ways to combine rule-based and statistical machine translation methods.
In 2002, Och published a paper titled "Discriminative Training and Maximum Entropy Models for Statistical Machine Translation" at the Annual Meeting of the Association for Computational Linguistics (ACL 2002), further proposing systematic methods for statistical machine translation. His paper won the Best Paper Award at ACL 2002. In July 2003, at an evaluation hosted by the National Institute of Standards and Technology (NIST/TIDES) in Baltimore, Maryland, Och achieved the best results. Using statistical methods and relying on bilingual parallel corpora, he constructed several machine translation systems from Arabic and Chinese to English in a short period. At the conference, Och proudly echoed the great Greek scientist Archimedes, saying, "Give me a place to stand, and I will move the world." Och proclaimed, "Give me enough parallel data, and you can have a translation system for any two languages in a matter of hours." His words reflect the vibrant exploratory spirit and ambition of the new generation of machine translation researchers.
As early as 1947, Warren Weaver proposed using cryptographic decoding methods for machine translation in his memo titled "Translation." This so-called "cryptographic decoding" method was essentially a statistical approach, aiming to solve machine translation problems using statistical methods. However, due to the lack of high-performance computers and large-scale online corpora at the time, implementing statistical machine translation was technically immature. Now, the situation has greatly changed; computers have significantly improved in speed and capacity, and large-scale online corpora are available for statistical use. In the 1990s, statistical machine translation flourished again, making Weaver's vision a reality.
In the early 1990s, IBM Research introduced a machine translation system. This system did not rely on comprehensive rules or linguistic knowledge but instead analyzed similar texts in two languages to discern patterns.
The idea was simple yet brilliant: a sentence in one language is split into words and matched with its counterpart in the other language. This operation is repeated approximately 500 million times, counting how often each word pairing occurs. For instance, counting how often "Das Haus" is translated as "house," "building," or "construction."
If "house" is the most frequent translation, the machine adopts it. Notably, no rules were set, and no dictionaries were used; all conclusions were based on statistics and the logic of "if everyone translates it this way, so will I." Thus, statistical machine translation (SMT) was born.

This method was more efficient and accurate than previous approaches and did not require linguists. The more texts used, the better the translation quality.
Figure: Inside Google's statistical translation, which calculates probabilities and also performs reverse statistics.
However, this method had a problem: how and when does the machine associate "Das Haus" with "building"? How do we know this is the correct translation?
The answer is we don't know initially. Initially, the machine assumes "Das Haus" has equal relevance to all words in the translated sentence. As "Das Haus" appears in other sentences and is associated with "house," its relevance increases by one. This is a classic task in university machine learning: "word alignment algorithm."
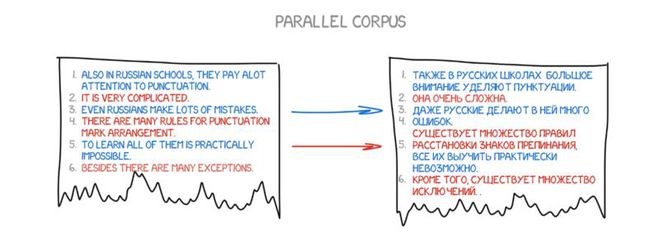
This machine requires millions of sentences in both languages to gather relevance statistics for each word. Where can we get this data? We extracted portions from the European Parliament and United Nations Security Council meetings, which provide translations for all member languages (you can download them here: LDC2013T06, Europarl).
Word-Based SMT
Initially, the first statistical translation systems segmented sentences into words because it was the most intuitive and logical method. IBM's first statistical translation model was called Model 1. Sounds fancy, right? Guess what they named the second system?
Model 1: "Bag of Words"
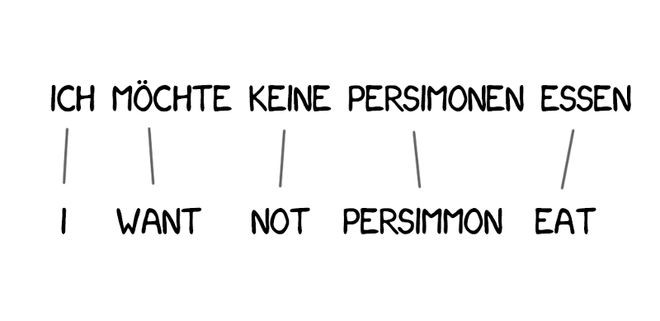
Model 1 used the classic method of segmenting sentences into words and counting them. It didn't consider word order. The tricky part was that sometimes multiple words could translate into one word. For example, "吃饭" can translate to "eat," but not vice versa ("eat" only translates to "吃").
Click here for simple examples implemented in Python: GitHub IBM-Model-1
Model 2: Considering Word Order
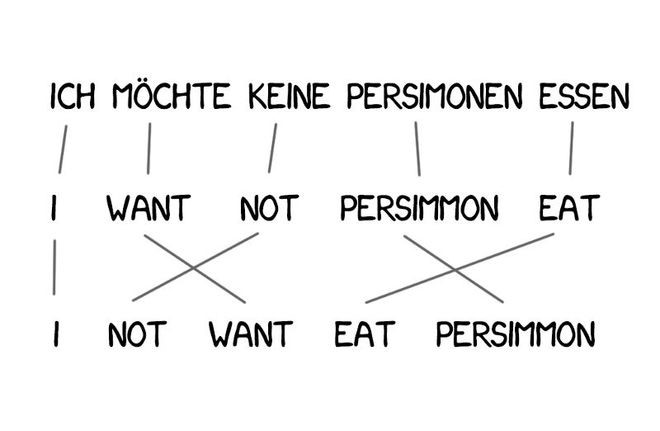
Model 1's problem was the lack of understanding of word order, which is crucial in some contexts.
Model 2 addressed this by remembering the typical position of words in the output sentence and rearranging them in intermediate steps to make the sentence sound more natural. This improved the results, but the final translation was still somewhat clunky.
Model 3: Additional Handling
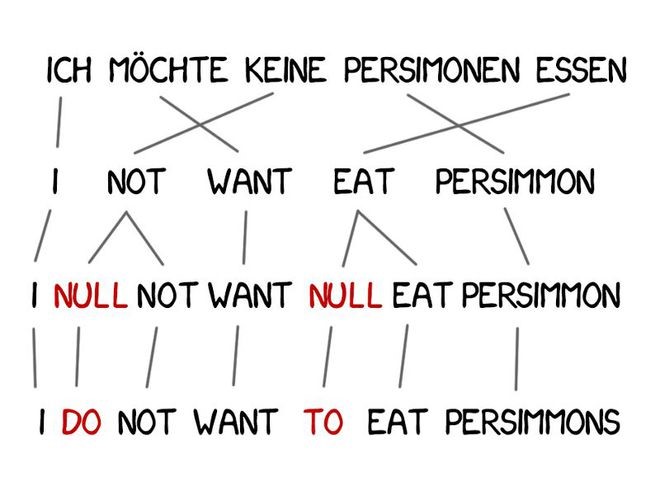
Some words frequently appear in translations, such as articles in German or "do" in English negations. "Ich will keine Persimonen" → "I do not want persimmons." To handle this, Model 3 added two extra steps:
1. Insert NULL markers when the machine feels new words are needed.
2. Select appropriate grammatical helpers or words for each marker.
Model 4: Word Alignment
Model 2 considered word alignment but didn't understand reordering. For instance, adjectives usually need to swap places with nouns, and no matter how well it remembers the order, it cannot improve the output. Therefore, Model 4 introduced the concept of "relative order," where the model learns if two words frequently switch places.
Model 5: Bug Fixes
Model 5 did not innovate functionally but added more parameters for learning and fixed word position conflicts.
Despite the revolutionary innovation that word-based systems brought to machine translation, they could not handle issues like capitalization, gender, and homophones. Each word was translated in a seemingly correct but isolated manner. These systems have been replaced by more advanced phrase-based methods.
Phrase-Based SMT
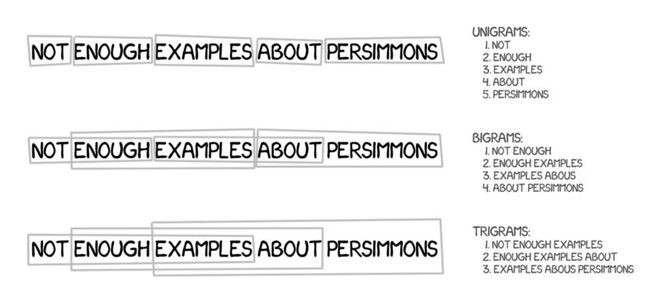
This method inherited all the principles of word-based translation: statistics, reordering, and lexical adjustments. However, it segmented text into phrases rather than words, based on n-grams, which are sequences of n consecutive words.
Therefore, the machine learns stable combinations of multiple words, significantly improving translation accuracy.
The challenge lies in the fact that not all phrases have simple grammatical structures. If someone knowledgeable in linguistics and sentence structures intervenes, the translation quality can significantly decline. Computational linguistics master Frederick Jelinek joked, "Every time I fire a linguist, the performance of the speech recognizer goes up."
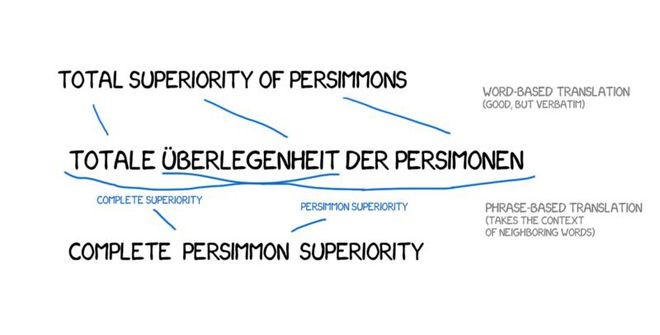
In addition to improved accuracy, phrase-based translation provided more ways to learn from bilingual texts. For word-based translation, exact matches of the source text are critical, excluding any literary or free translations. Phrase-based translation did not have this issue. Researchers even parsed different language news websites to improve translations.
Since 2006, everyone started using this method. By 2016, Google Translate, Yandex, Bing, and other high-end online translation services had emerged, using phrase-based methods. Some may recall a time when Google Translate produced perfect sentence translations, while others were nonsensical. Those incoherent translations came from phrase-based translation.
Old rule-based methods could stably provide predictable but poor results, while statistical methods were surprising yet mysterious. Google Translate unhesitatingly translated "three hundred" to "300." This is known as statistical bias.
Phrase-based translation became very popular, so much so that when people refer to "statistical machine translation," they usually mean phrase-based translation. Until 2016, all research praised phrase-based translation as the most advanced method. However, no one anticipated that Google was preparing to revolutionize our understanding of machine translation.
Syntax-Based SMT
This method needs a brief introduction. For many years before neural networks, syntax-based translation was considered the "future of machine translation," but this idea never materialized.
Supporters of syntax-based translation argued for merging it with rule-based methods. It was necessary to perform very precise grammatical analysis of sentences—identifying the subject, predicate, and other parts—then create sentence trees. Using these trees, the machine could learn to convert grammatical units between languages and translate the rest through lexical or phrase-based methods. This would solve the word alignment issue comprehensively.
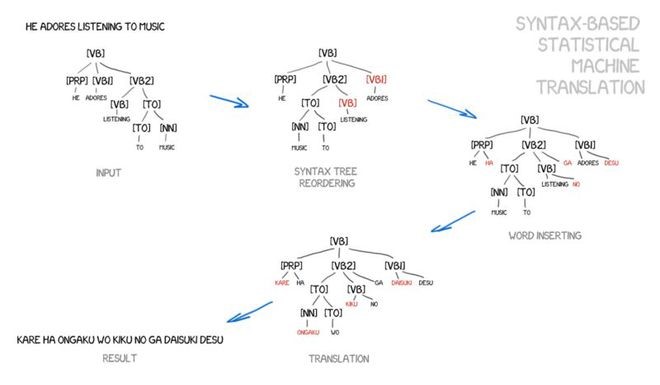
Figure: An example taken from the paper and slides by Yamada and Knight.
However, the problem was that grammatical analysis was poorly executed, even though we thought it was resolved long ago (since we had many ready-made language corpora). Every attempt to solve more complex issues than parsing subjects and predicates with syntax trees ended in failure.
Statistical Machine Translation (SMT) has elevated the development of machine translation to a new level. By acquiring translation knowledge from large-scale real corpora, it has significantly improved the means of obtaining linguistic knowledge and effectively enhanced the quality of translations. SMT trains model parameters using parallel corpora, eliminating the need for manually written rules. This direct training approach reduces labor costs and shortens development cycles, making SMT the core technology for online machine translation systems of companies like Google, Microsoft, and Baidu.
However, SMT still faces several issues. Despite acquiring linguistic knowledge from real corpora, it relies on human experts to design features representing various translation knowledge sources. The structural transformation between different languages is highly complex, and manually designed features cannot cover all linguistic phenomena. Moreover, SMT's rules are heavily dependent on the corpus, making it challenging to incorporate complex linguistic knowledge. Even with large-scale corpora for training, the problem of data sparsity remains significant. Therefore, further improvements in SMT technology are necessary.