Development of AI and MT ---- RBMT
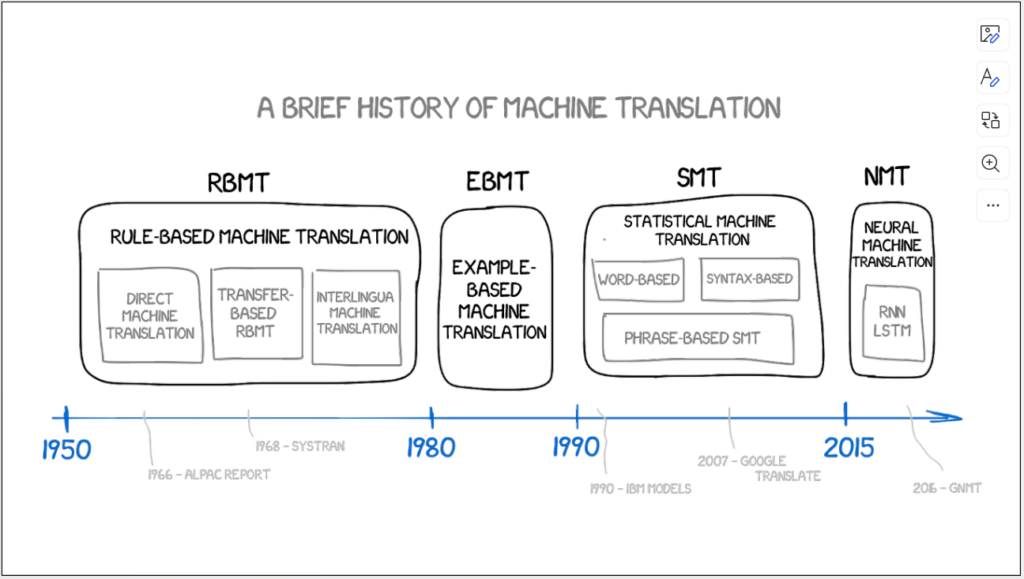
As we all know, our course is titled "Artificial Intelligence and Translation." So, what exactly is the relationship between artificial intelligence and translation? Do their developments influence each other? Rather than saying that the focus of our early sessions is on artificial intelligence and translation, it would be more accurate to say that we are focusing on artificial intelligence and machine translation (in the early sessions). Therefore, let’s take a detailed look at this chart, starting with RBMT, to explain machine translation and artificial intelligence.
If you want a simple and quick understanding, along with some interesting illustrations, you can click on the link below for a simplified version of the explanation: https://www.163.com/dy/article/DDHBVQGK0511FQO9.html
If you prefer a more rigorous and comprehensive view of RBMT, you can refer to the paper below: 冯志伟.机器翻译与人工智能的平行发展[J].外国语(上海外国语大学学报),2018,41(06):35-48.
Next, most of the content is mainly referenced from these two sources, but we have added some of our own ideas and expressions. First, we need to provide a brief overview of the background of machine translation, specifically the early developments in artificial intelligence and machine translation.
In the early 1930s, French scientist Arctuni clearly proposed the idea of using machines for language translation.
In 1933, the story officially began.
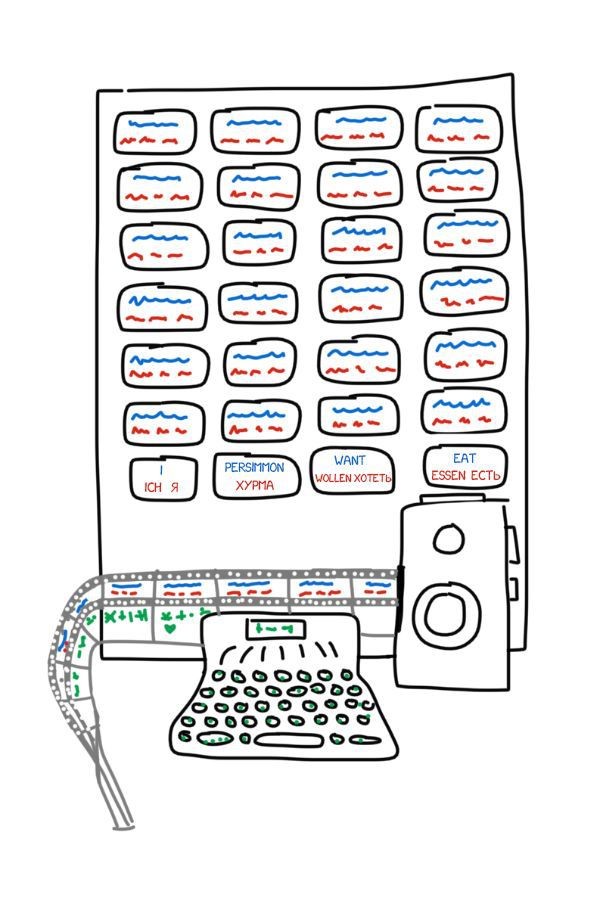
Soviet scientist Peter Troyanskii submitted a paper titled "A Machine for the Selection and Printing of Words During Bilingual Translation" to the Soviet Academy of Sciences. This invention was quite simple and included cards in four languages, a typewriter, and an old-fashioned film camera.
The operator would take the first word from the text, find the corresponding card, take a photograph of it, and type out the word's form (such as noun, plural, possessive, etc.) on the typewriter. The keys of the typewriter constituted a feature code. Then, using tape and the camera's film, a frame-by-frame combination of words and morphological features was created.
Despite this, the invention was deemed "useless," a common occurrence in pre-Soviet Russia. Troyanskii worked on this invention for 20 years until his death from angina pectoris. No one knew about this machine until 1956, when two former Soviet scientists discovered his patent.
Subsequently, the Cold War began.
In 1946, the United States designed and built the world's first electronic computer, ENIAC, and the concept of using computers for automatic language translation was proposed in the same year.
In 1949, Weaver published a memorandum titled "Translation," formally proposing the use of electronic computers for machine translation. He believed that translation was similar to decoding a cipher.
On January 7, 1954, at IBM's New York headquarters, the Georgetown-IBM experiment began. IBM's 701 computer automatically translated 60 Russian sentences into English, marking the first machine translation in history.
"A girl who did not understand Russian typed the Russian text on IBM cards. The 'computer' translated the text into English at an astonishing speed of 2.5 lines per second on an automatic printer." — IBM reported in The New York Times.

However, this triumphant headline concealed a small detail. It did not mention that the examples used for translation were carefully selected and tested, excluding any ambiguities. This system was essentially no different from a phrasebook. Nonetheless, countries including Canada, Germany, France, and especially Japan, entered into competition, with everyone joining the race for machine translation.
As early as September 1947, British mathematician Alan Turing mentioned in a report to the National Physical Laboratory of Britain that "machine translation" could demonstrate the "intelligence" of computers when he discussed his plans to build a computer.
It can be seen that the history of machine translation predates artificial intelligence by two years. We believe that the success of the 1954 machine translation experiment may have contributed to the birth of artificial intelligence in 1956 to some extent. Machine translation and artificial intelligence are closely intertwined. After the 1956 Dartmouth Conference, artificial intelligence developed rapidly.
Artificial intelligence also turned its focus to natural language, making Natural Language Understanding (NLU) a key area of AI research.
In the subsequent 40 years, machine translation experienced a downturn, and artificial intelligence faced a harsh winter. Despite the initial enthusiasm for AI, early machine translations were criticized for their poor readability by users.
In 1966, the Automatic Language Processing Advisory Committee (ALPAC) in the United States issued a famous report declaring that machine translation was expensive, inaccurate, and hopeless. They recommended focusing more on dictionary development, leading American researchers to withdraw from the machine translation race for nearly a decade.
As machine translation entered a period of decline starting in the 1970s, optimism in the field of artificial intelligence also began to wane. Researchers found that AI programs could only solve the simplest parts of the problems they attempted to address, with strict limitations on the scenarios. The insufficient storage space and computing power of computers at that time could not meet the needs of AI.
As a result, DARPA terminated funding for AI projects in 1970. By the mid-1970s, it had become very difficult to find financial support for AI projects. Consequently, AI research entered its first winter. Thus, in the late 1960s and early 1970s, both machine translation and artificial intelligence experienced downturns.
Even so, scientists laid the foundation for modern natural language processing through continuous trials, research, and development. Today's search engines, spam filters, and personal assistants all owe their existence to the international competition of those years.
During the resurgence of machine translation, researchers widely recognized that the differences between the source and target languages in machine translation were not only reflected in vocabulary but also in syntactic structures. To achieve highly readable translations, significant effort had to be put into automatic syntactic analysis. Subsequently, considerable progress was made in automatic syntactic analysis within machine translation.
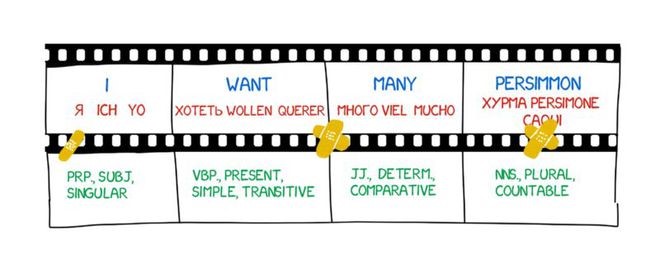
As early as 1957, American scholar V. Yingve pointed out in his paper "Framework for Syntactic Translation" that a good machine translation system should accurately describe both the source language and the target language independently. Yingve advocated that machine translation could be carried out in the following three stages:
First stage: Representing the structure of the source language text with coded structural markers;
Second stage: Converting the structural markers of the source language text into the structural markers of the target language text;
Third stage: Generating the output text of the target language.
The first stage involves only the source language and is unaffected by the target language. The third stage involves only the target language and is unaffected by the source language.
It is only in the second stage that both the source language and the target language are involved. In the first stage, in addition to lexical analysis of the source language, syntactic analysis of the source language is also necessary to represent the structure of the source language text as coded structural markers. In the second stage, in addition to lexical conversion between the source language and the target language, structural conversion between the source language and the target language is also necessary to change the structural markers of the source language into those of the target language.In the third stage, in addition to lexical generation of the target language, syntactic generation of the target language is also necessary to correctly output the target language translation text.
Yingve's ideas were widely disseminated during this period and were generally accepted by machine translation system developers. As a result, machine translation systems of this period almost all prioritized phrase-based syntactic analysis and achieved significant progress in this area. Since such machine translation systems are based on language rules, they are called Rule-Based Machine Translation (RBMT) systems or Phrase-Based Machine Translation (PBMT) systems.
Rule-basedmachine translation: RBMT
The idea of rule-based machine translation first appeared in the 1970s. Scientists, based on their observations of translators' work, attempted to drive large, cumbersome computers to replicate translation behavior. The components of these systems included:
Bilingual dictionaries (e.g., Russian -> English)
A set of language rules formulated for each language (e.g., nouns ending with specific suffixes like -heit, -keit, -ung, etc.)
That's it. If necessary, the system could also supplement with various specialized rules, such as for names, spelling correction, and transliterations.

PROMPT and Systran are the most famous examples of RBMT systems. Just a glance at Aliexpress can give you a sense of that golden era.
However, there are some subtle differences and variations between them.
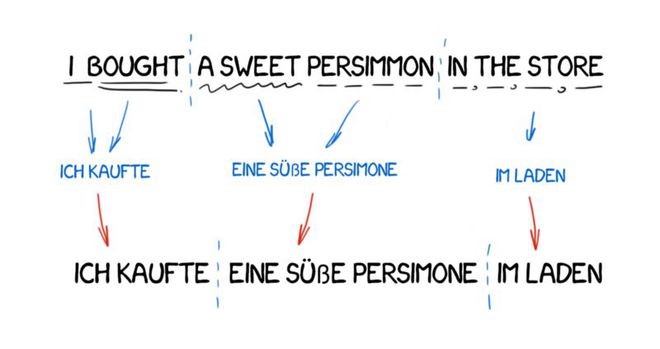
Direct Translation Method
This type of machine translation is the most straightforward. It divides the text into words, translates them, makes slight morphological adjustments, and polishes the grammar to make the whole sentence sound coherent. Countless days and nights, trained linguists wrote rules for each word.
The output is the translated sentence. Usually, the translated sentence sounds a bit awkward. It seems like the linguists wasted their time.
Modern language systems no longer use this method, so linguists can breathe a sigh of relief.
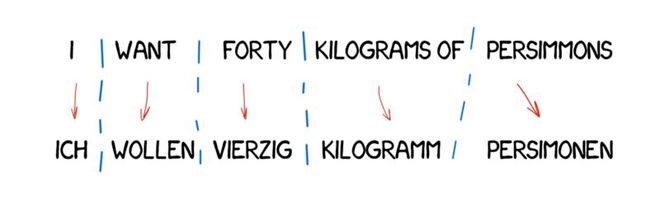
Transformation Translation Method
This translation method is quite different from direct translation. First, we determine the grammatical structure of the sentence, much like we learned in school. Then, we adjust the overall structure of the sentence, rather than just the words. This step helps us achieve a more reasonable word order. At least, in theory, it does.
However, in practice, these systems still rely on word-by-word translation and strict linguists. On one hand, it introduces simplified general grammatical rules. But on the other hand, the number of lexical structures increases significantly compared to individual words, leading to more complex translations.
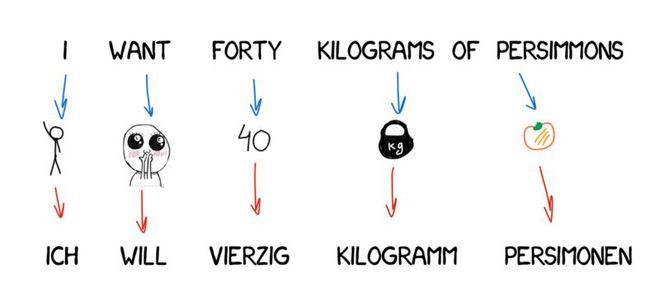
Interlingua Method
This method transforms the source text into a universal intermediate language (Interlingua) representation. This is the very interlanguage dreamed of by Descartes: a meta-language that follows universal rules and turns translation into a simple "back-and-forth" task. The next step is to convert the interlanguage into any target language. Isn't that amazing?
Because both involve transformation, the Interlingua method is often confused with transformation translation systems. The difference with the Interlingua method is that the language rules are applied to each language and the interlanguage, independent of the language pairs being translated. This means we can add a third language to the Interlingua system and translate between all three languages. However, the transformation translation method cannot achieve this.
This theory sounds perfect, but reality is quite different. Creating such an interlanguage is extremely challenging, so much so that many scientists have dedicated their entire lives to this endeavor. Although they did not succeed, their hard work has brought us today's levels of morphology, syntax, and semantics. Just the semantic text theory alone requires enormous investment!
The Interlingua method will return sooner or later, and we eagerly await its comeback.
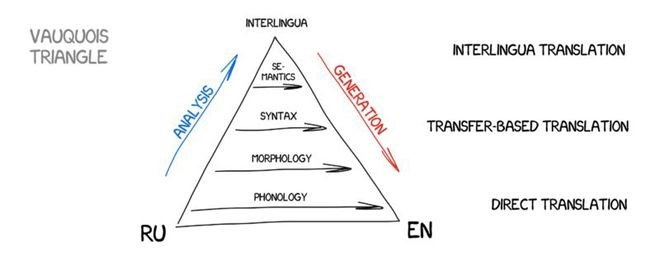
As you can see, all RBMT systems are clumsy and cumbersome, so we only use them in special occasions, such as weather forecast translations. The commonly mentioned advantages of RBMT include its precise morphology (it doesn't create ambiguities with words), repeatable results (all translators can achieve the same results), and the ability to be tailored to specific topics (e.g., teaching economists programming-specific terminology).
Even if someone successfully created the ideal RBMT and linguists reinforced it with all the spelling rules, we would always encounter exceptions: irregular verbs in English, separable prefixes in German, suffixes in Russian, and slight variations in human expression. Addressing all these subtle differences would require an enormous amount of human effort.
There are also homonyms. The same word can have different meanings in different contexts, which can affect the translation. Take the following sentence, for example: "I saw a man on a hill with a telescope." This could be translated in several ways: "我看到山上有个男人拿着望远镜"; or "我站在山上透过望远镜看到一个男人"; or "我透过望远镜看到山上站着一个男人." Additionally, "saw" can also be translated as "锯" (the verb), etc.
“我看到山上有个男人拿着望远镜”; or “我站在山上透过望远镜看到一个男人”; or “我透过望远镜看到山上站着一个男人.” Additionally, “saw” can also be translated as “锯” (the verb), etc.
Languages did not develop according to a fixed set of rules, although linguists are fond of rules. Over the past 300 years, languages have been significantly influenced by the history of invasions. How do you explain that to a machine?
Forty years of the Cold War did not help us find the ultimate solution.
RBMT is dead.
As machine translation experienced a revival, artificial intelligence also gradually recovered. In 1980, Carnegie Mellon University developed an expert system for DEC, which could provide valuable decision-making advice and help DEC save $40 million annually. AI once again demonstrated its power. In 1982, Japan invested heavily in developing the fifth-generation computer, then called the "artificial intelligence computer." Thus, AI emerged from its first winter and entered its second boom. The 1980s saw significant innovations in AI with mathematical models. In 1986, the multi-layer neural network and back-propagation algorithm were proposed, and in 1989, an intelligent machine capable of playing chess with humans was designed. AI technology also played a role in the postal service, using AI networks to automatically recognize postal codes on envelopes with an accuracy rate of over 99%, surpassing the recognition level of ordinary people.
However, these AI technologies could only be realized on large computers, which were difficult to maintain and expensive, limiting the application of AI technology.
In the late 1980s, IBM introduced the personal computer (PC), which was inexpensive and easy to use, quickly entering individual households.
IBM introduced the personal computer (PC), which was inexpensive and easy to use, quickly entering individual households. Compared to PCs, AI systems based on large computers seemed esoteric and unappealing, with few people willing to use them.
As a result, the funding allocated by the government for AI research decreased, AI research institutions saw dwindling activity, and AI researchers switched careers, leading to a desolate landscape. AI entered its second winter.
In summary, from the development history of AI and machine translation, it can be seen that in the early stages, especially during the period from the birth of machine translation to the gradual decline of rule-based machine translation (RBMT), AI and machine translation complemented each other, jointly experiencing winters and revivals. After their revival, they both entered a new period of challenges. However, with continuous technological advancement and innovation, the future of AI and machine translation remains full of hope and potential.