AI与MT发展历程——RBMT篇
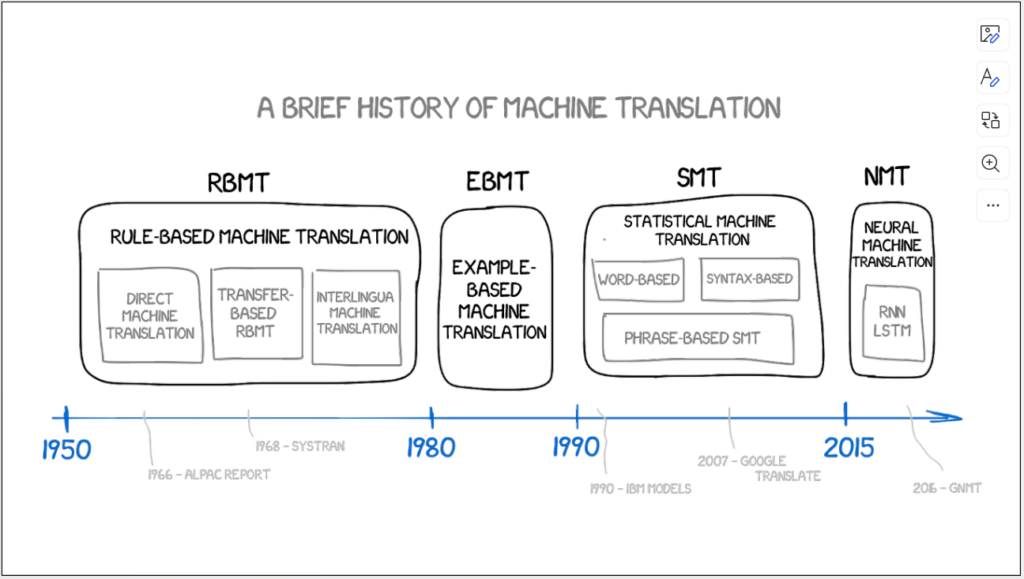
众所周知,我们的课程名是人工智能与翻译,那么人工智能与翻译到底有什么关系呢?这两者的发展是否相互影响呢?与其说我们这节课前期重点讲的是人工智能与翻译,不如说重点讲的是人工智能与机器翻译(前期课程),所以我们来详细看一下这张图,从RBMT开始详细讲解机器翻译与人工智能。
那如果您想要简单快速地看懂,并且有一些趣味配图的话,您可以点击下方这个链接,这个是比较简易的版本的回答https://www.163.com/dy/article/DDHBVQGK0511FQO9.html
如果您更想要严谨,并且全面地看待RBMT,那可以看下方这篇论文。冯志伟.机器翻译与人工智能的平行发展[J].外国语(上海外国语大学学报),2018,41(06):35-48.
接下来大部分内容主要参考了这两份资料,不过在其中加了一些我们自己的想法和表达,首先我们要再讲一下机器翻译的前情提要,也就是关于人工智能和机器翻译的前期情况。
20世纪30年代之初,法国科学家阿尔楚尼明确地提出了用机器来进行语言翻译的想法。
1933年,故事正式开始。
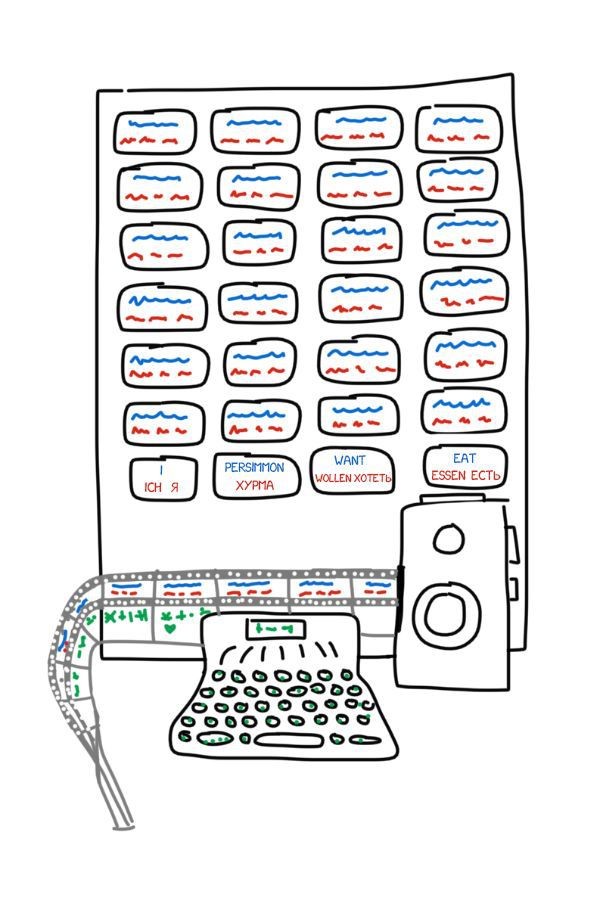
前苏联科学家 Peter Troyanskii*(特洛扬斯基) 向苏联科学院提交了一篇《双语翻译时用于选择和打印文字的机器》的论文。这项发明非常简单,包括有4种语言的卡片、一部打字机、以及一部旧式的胶卷照相机。
操作人员从文本中拿出第一个单词,找到相应的卡片,然后拍张照片,并在打字机上打出词态,如名词,复数,所有格等。这部打字机的按键构成了一种特征编码。然后利用胶带和照相机的胶卷制作出一帧帧的单词与形态特征的组合。
尽管如此,这项发明被认作“无用”,这种事情在前苏联习以为常。Troyanskii为完成此项发明努力了20年,直到他死于心绞痛。世上无一人知道这个机器,直到1956年两位前苏联科学家发现了他的专利。
随后冷战爆发。
1946年,美国设计并制造出了世界上第一台电子计算机 ENIAC,同年提出了利用计算机进行语言自动翻译的构想。
1949年,韦弗发表了一份以《翻译》为题的备忘录,正式提出了用电子计算机进行机器翻译问题。他认为,翻译类似于解读密码的过程。
1954年1月7日,在IBM纽约总部,Georgetown-IBM实验启动了。IBM的701型计算机将60个俄语句子自动翻译成英语,这是历史上首次的机器翻译。
“一位不懂俄语的女孩在IBM的卡片上打出了俄语信息。‘电脑’以每秒2.5行的惊人速度,在自动打印机上迅速完成了英语的翻译。”——IBM报道于美国《纽约时报》

然而,这份洋洋得意的头条却隐藏了一个小细节。它并未提到翻译所用到的例子是经过了精心的挑选和测试,并排除了任何歧义。这个系统实际上无外乎形同一本常用语手册。然而,包括加拿大、德国、法国、尤其是日本,各国间就此展开了竞争,所有人都加入了机器翻译的比拼。
早在 1947 年 9 月,英国数学家图灵( Alan Turing) 在一份写给英国国家物理实验室的报告中谈到他建造计算机的计划时就指出,“机器翻译”( Machine Translation) 可以显示计算机的“智能” 。
可以看出,机器翻译的历史比人工智能还早两年,我们认为,1954年机器翻译试验的成功也许在一定程度上促成了 1956 年人工智能的诞生,机器翻译与人工智能有着不解之缘。 在1956年的达特茅斯会议之后,人工智能迅速地发展起来。
人工智能还把研究的视线投向了自然语言,把自然语言理解( Natural Language Understanding,简称 NLU) 作为人工智能研究的重要领域。
在以后的40年中,是属于机器翻译的低潮和人工智能的严冬。就在人工智能风生水起的热潮中,早期机器翻译的译文由于其可读性很差,而受到了广大用户的批评。
1966年,美国的自动处理咨询委员会(Automatic Language Processing Advisory Committee:ALPAC),在一篇著名的报道中宣称机器翻译昂贵、不准确、且没有希望。他们建议应该更注重词典的开发,这导致了美国研发人员退出了机器翻译竞赛将近10年之久。
随着机器翻译进入萧条期,从1970年开始,在人工智能的领域,人们的乐观情绪也渐渐冷淡下来。 研究人员发现,人工智能程序只能解决他们尝试解决的问题中的最简单的那一部分,对于场景的要求有严格的限制,由于当时计算机的存储空间和计算能力都不足,难以满足人工智能的需要。
于是,DARPA 在1970年终止了对人工智能项目的拨款,到了20世纪70年代中期,人工智能项目已经很难找到资金的支持了。于是人工智能研究进入了它的第一个严冬。 这样,20世纪60年代末期和70年代初期,不论是机器翻译还是人工智能都先后进入了低潮。
即便如此,科学家们还是通过不断的尝试、研究和开发奠定了现代自然语言处理的基础。如今所有的搜索引擎、垃圾邮件过滤器、以及个人助手都要归功于那些年国家间相互的比拼。
在机器翻译的复苏期,研究者们普遍认识到,机器翻译中的源语言和目标语言的差异,不仅只表现在词汇的不同上,而且,还表现在句法结构的不同上,为了得到可读性强的译文,必须在自动句法分析上多下功夫。此后机器翻译在自动句法分析方面取得了不少的成果。
早在 1957 年,美 国 学 者 英 格 维 ( V.Yingve) 在《句法翻译的框架》( Framework for syntactic translation) 一文中就指出,一个好的机器翻译系统,应该对源语言和目标语言都做出恰如其分的描写,这样的描写应该互不影响,相对独立。英格维主张,机器翻译可以分为如下三个阶段来进行。
第一阶段: 用代码化的结构标志来表示源语言的文本结构;
第二阶段: 把源语言的文本结构标志转换为目标语言的文本结构标志;
第三阶段: 构成目标语言的输出文本。
第一阶段只涉及源语言,不受目标语言的影响,第三阶段只涉及目标语言,不受源语言的影
响,只是在第二阶段才涉及到源语言和目标语言二者。在第一阶段,除了作源语言的词法分析之外,还要进行源语言的句法分析,才能把源语言文本的结构表示为代码化的结构标志。在第二阶段,除了进行源语言和目标语言的词汇转换之外,还要进行源语言和目标语言的结构转换,才能把源语言的结构标志改变为目标语言的结构标志。在第三阶段,除了作目标语言的词法生成之外,还要进行目标语言的句法生成,才能正确地输出目标语言译文的文本。
英格维的这些主张,在这个时期广为传播,并被机器翻译系统的开发人员普遍接受,因此,这个时期的机器翻译系统几乎都把基于短语的句法分析( Phrase-Based Syntactic Analysis) 放在第一位,并且在基于短语的句法分析方面取得了很大的成绩。由于这样的机器翻译系统都是以语言规则为基础的,所以叫做基于规则的机器翻译系统( Rule-Based Machine Translation,简称 RBMT) ,或者叫做基于短语的机器翻译系统( Phrase-Based Machine Translation,简称 PBMT) 。
基于规则的机器翻译(RBMT)
基于规则的机器翻译的想法第一次出现是在70年代。科学家根据对翻译者工作的观察,试图驱使巨大笨重的计算机重复翻译行为。这些系统的组成部分包括:
双语词典(俄语->英文)
针对每种语言制定一套语言规则(例如,名词以特定的后缀-heit、-keit、-ung等结尾)
如此而已。如果有必要,系统还可以补充各种技巧性的规则,如名字、拼写纠正、以及音译词等。

PROMPT和Systran是RBMT系统中最有名的例子。看一眼Aliexpress 就能感受到那个黄金时代的气息。
但是它们还有一些细微的差别和变体。
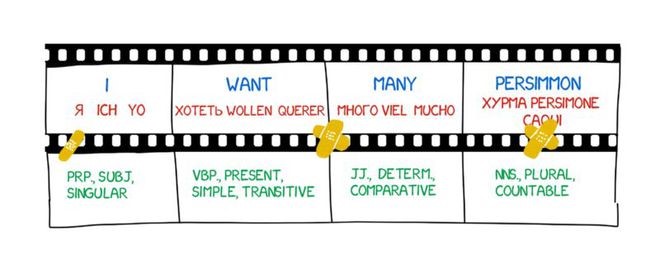
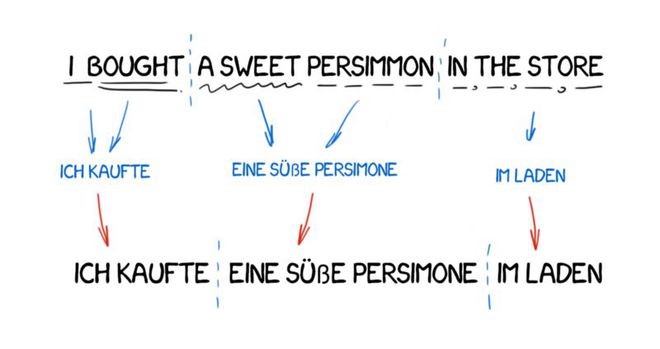
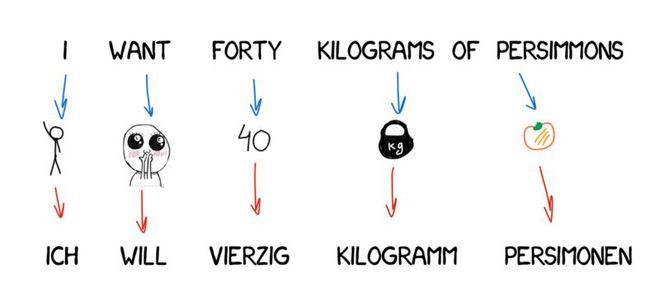
直接翻译法
这种机器翻译最直白。它把文本划分成单词,进行翻译,然后进行轻微的形态调整,再润色语法,让整句话听起来像回事儿。多少个日日夜夜,训练有素的语言学家为每个单词写规则。
输出即为翻译后的句子。通常,翻译的句子听起来都有点蹩脚。似乎语言学家白白浪费了他们的时间。
现代语言系统不再使用这样的方法,所以语言学家可以松口气了。
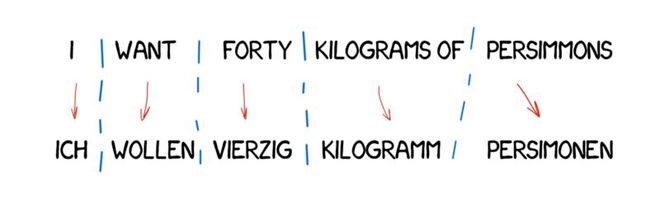
转换翻译法
这种翻译方法与直接翻译大相径庭,首先我们决定句子的语法结构,就像我们在学校里学到的一样。然后我们调整句子的整体结构,而不是单词。这一步可以帮助我们获得十分合理的单词顺序。至少理论上是这样的。
但是在实践中,这种系统依然依赖逐词的翻译和墨守成规的语言学家。一方面,它引入了简化的一般语法规则。但另一方面,词汇结构的数量与单个单词相比大幅度增加,从而导致翻译更加复杂。
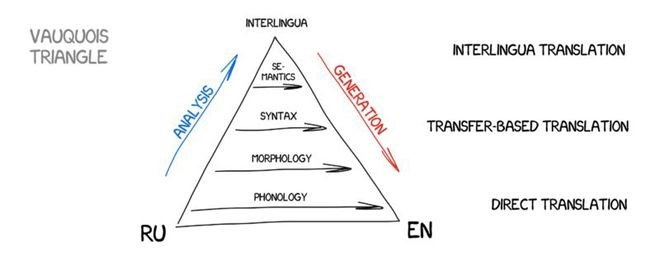
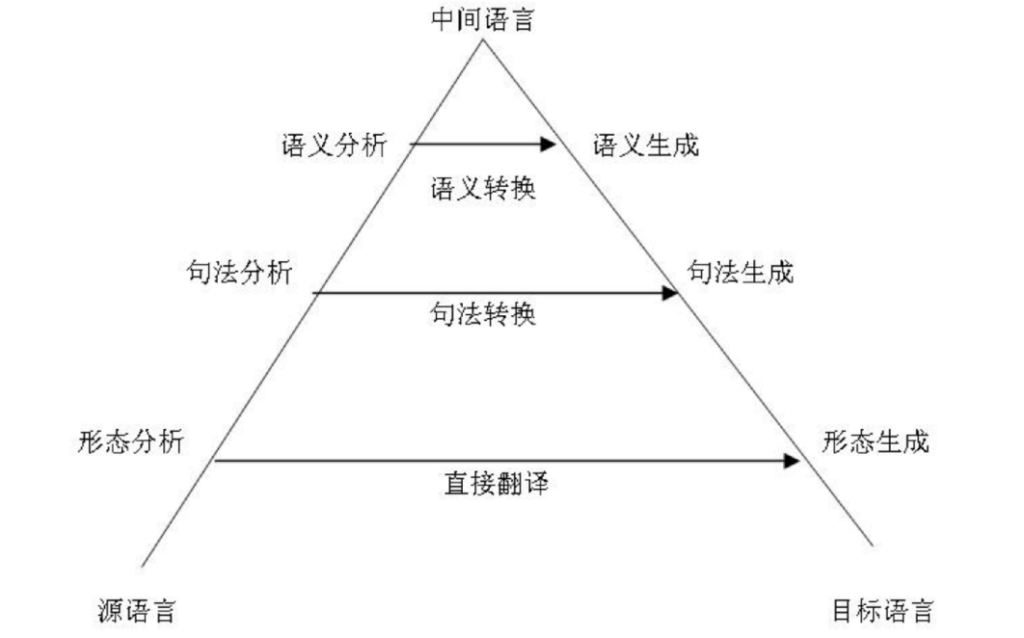
中间语言法
这个方法将源文本转变成全世界统一的一种中间语言(Interlingua)表达形式。这正是笛卡尔梦想的中间语言:一种元语言,遵循通用规则,并可以将翻译转化为简单的“来回”的任务。下一步,中间语言可以转换成任何目标语言,是不是很神奇?
因为都涉及转换,所以中间语言法通常与转换翻译法的系统相混淆。中间语言法的不同之处在于语言规则针对每种语言和中间语言,而与互译的语言对无关。这意味着我们可以在中间语言系统中添加第三种语言,并且可以在所有三种语言之间互相翻译。但是转换翻译法做不到这一点。
这个理论听起来似乎很完美,但是现实却并非如此。创建这样一种中间语言难度极其高,乃至很多科学家毕生都在为此而奋斗。虽然没有成功,但是他们的辛劳为我们带来了今天的形态、语法、以及语义等表现层次。仅仅是意义文本理论本身就需要耗费巨资!
中间语言法迟早会回来的,让我们翘首以待。
如你所见,所有的RBMT都很蠢笨和可怕,所以我们仅在特殊场合使用它们,比如天气预报翻译等等。人们经常提到的RBMT的优点包括它的精准的形态(不会给单词带来歧义)、可重复的结果(所有翻译器都可以得到相同的结果)、以及可以调节到特定主题的功能(比如教经济学家编程专用术语)。
即便有人成功地创建了理想的RBMT,并且语言学家用所有的拼写规则强化它,我们也总是会遇到一些例外:英语中的非规则动词,德语中可分离的前缀,俄语中的后缀,以及人们在表达的时候会有些许的差异。如果要解决这些所有的细微差别,将耗费巨大的人力。
还有同音异义词。相同的单词在不同的上下文环境里有不同的意思,这也会影响翻译的变化。看看下面这句话可以理解为几个意思:I saw a man on a hill with telescope? 比如可以翻译成:我看到山上有个男人拿着望远镜;也可以翻译成:我站在山上透过望远镜看到一个男人;还可以翻译成:我透过望远镜看到山上站着一个男人;此外saw还可以翻译成“锯”(动词)等等。
“我看到山上有个男人拿着望远镜”; or “我站在山上透过望远镜看到一个男人”; or “我透过望远镜看到山上站着一个男人.” Additionally, “saw” can also be translated as “锯” (the verb), etc.
语言不是根据固定的一套规则发展而来的,尽管语言学家很喜欢规则。过去的300年中,语言在很大程度上受到了侵略史的影响。你又如何向一台机器解释呢?
40年的冷战未能帮助我们找到最终的解决方案。
RBMT已死。
随着机器翻译的复苏,人工智能也逐渐复苏。1980年,美国卡内基梅隆大学为DEC公司研制出一个专家系统( expert system) ,这个专家系统可以在决策方面提供有价值的建议,帮助 DEC 公司每年节省 4000 万美元的费用,人工智能重新显示出其威力。1982 年,日本投入巨资,开发第五代计算机,当时叫作“人工智能计算机”。于是人工智能走出了第一次的严冬,进入了它的第二次高潮。20 世纪80年代人工智能在数学模型方面有重大创新,1986 年提出了多层神经网络( multi- layer neural network) 和反向传播算法( back-propagation algorithm) ,1989 年设计出能与人类下象棋的智能机器,人工智能技术还在邮政中发挥了作用,使用人工智能网络来自动识别信封上的邮政编码,识别正确率达到 99% 以上,超过了普通人的识别水平。
不过这些人工智能技术都是要在大型计算机上才能实现,这样的大型计算机,维护不易,
费用高昂,限制了人工智能技术的应用。20世纪80年代后期IBM公司推出了个人计算 机
( personal computer,简称PC机) ,这种PC机费用低廉,使用简单,很快进入个人的家庭,与PC机相比,建立在大型计算机基础上的人工智能系统显得曲高和寡,黯然失色,很少有人乐意使用。
于是,政府拨给人工智能研制的经费越来越少,人工智能的研究单位“门前冷落鞍马稀”,人工智能的研究人员纷纷跳槽改行,显得非常冷清,人工智能又进入了它的第二次严冬。
综上所述,从人工智能和机器翻译的发展历程中可以看出,在早期阶段,尤其是在机器翻译诞生到基于规则的机器翻译(RBMT)逐渐衰落的这段时间里,人工智能和机器翻译相辅相成,共同经历了严冬和复苏。在复苏之后,二者又再次进入了一个新的挑战期。然而,随着技术的不断进步和创新,人工智能和机器翻译的未来仍然充满希望和潜力。