AI与MT发展历程——SMT篇
统计型机器翻译系统(SMT)
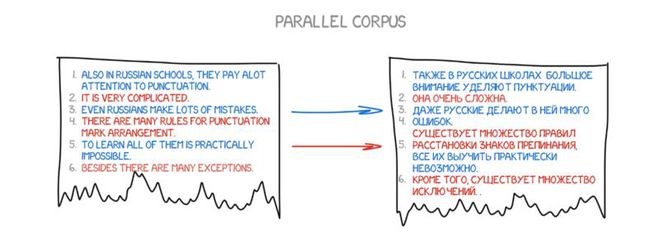
1993年7月,在日本神户召开的第四届机器翻译高层会议(MT Summit IV)上,英国学者哈钦斯在会议的特约报告中指出,自1989年以来,机器翻译的发展进入了一个新纪元。这个新纪元的突出标志是在基于规则的机器翻译技术中引入了语料库方法,包括统计方法、基于实例的方法、通过语料加工手段将语料库转化为语言知识库的方法等。这些方法可以从大规模真实文本语料库中获取语言学知识,而不是单凭语言学家的直感或语法书上的规则,从根本上改变了机器翻译获取语言学知识的手段。这种基于大规模真实文本处理的机器翻译,推动了实现战略目标的转移,推进了机器翻译进入一个崭新的阶段,基于规则的机器翻译发展为统计机器翻译(SMT)。
随着战略目标转移的进程,语料库方法渗透到了机器翻译研究的各个方面,一些基于语料库的统计机器翻译系统如雨后春笋般涌现。为了弥补统计机器翻译中常见的数据稀疏问题,一些机器翻译系统巧妙地结合了基于语料库的概率统计方法和基于规则的逻辑推理方法,取得了显著成果。
2000年,在约翰·霍普金斯大学的暑期机器翻译讨论班上,来自南加州大学、罗切斯特大学、约翰·霍普金斯大学、施乐公司、宾夕法尼亚大学、斯坦福大学等学校和企业的研究人员对统计机器翻译进行了讨论。由年轻博士研究生弗朗茨·约瑟夫·奥赫(Franz Josef Och)为主的13位科学家撰写了一份总结报告,标题为《统计机器翻译的句法》(Syntax for Statistical Machine Translation)。报告提出了将基于规则的机器翻译方法和统计机器翻译方法结合的有效途径。
奥赫在2002年国际计算语言学会议(ACL2002)上发表了题为《统计机器翻译的分辨训练与最大熵模型》(Discriminative Training and Maximum Entropy Models for Statistical Machine Translation)的论文,进一步提出了统计机器翻译的系统性方法,这篇论文获得了ACL2002大会的最佳论文奖。2003年7月,在美国马里兰州巴尔的摩由美国国家标准与技术研究所(NIST/TIDES)主持的评比中,奥赫获得了最佳成绩,他使用统计方法,依靠双语平行语料库,在很短的时间内构建了从阿拉伯语和汉语到英语的多个机器翻译系统。在这次会议上,奥赫自豪地引用了古希腊科学家阿基米德的话:“只要给我一个支点,我就能撬动地球。”奥赫表示,“只要给我足够的平行数据,我就能在几小时内为任何两种语言构建出一个机器翻译系统。”这番话反映了新一代机器翻译研究者的探索精神和豪情壮志。
早在1947年,韦弗在他的备忘录《翻译》中就提出使用解读密码的方法进行机器翻译,这种方法实际上是一种统计方法,旨在通过统计解决机器翻译问题。然而,当时缺乏高性能计算机和大规模联机语料库,使得这种方法难以实现。如今,随着计算机速度和容量的显著提高以及大规模联机语料库的可用性,统计机器翻译在20世纪90年代再度兴盛,韦弗的预见得以实现。
在1990年早期,IBM研究中心的一台机器翻译系统首次问世。它并不了解整体的规则和语言学,而是分析两种语言中的相似文本,并试图理解其中的模式。
这个想法很简单却很出色。相同的一个句子用两种语言分割成单词,然后相互匹配。将这种操作重复大约5亿次,并对每个单词的匹配结果进行计数,如统计单词“Das Haus”被翻译成“house”、“building”、“construction”的次数。
如果大多数时候被翻译成了“house”,那么机器就会采用这个翻译。请注意我们并没有设置任何规则,也没有用到任何词典,所有的结论都是机器根据统计以及“如果大家这么翻译,那我也这么翻译”的逻辑得出的 。于是统计型机器翻译诞生了。

这种方法比之前的方法更高效且准确,而且还不需要语言学家。使用的文本越多,翻译效果就越佳。
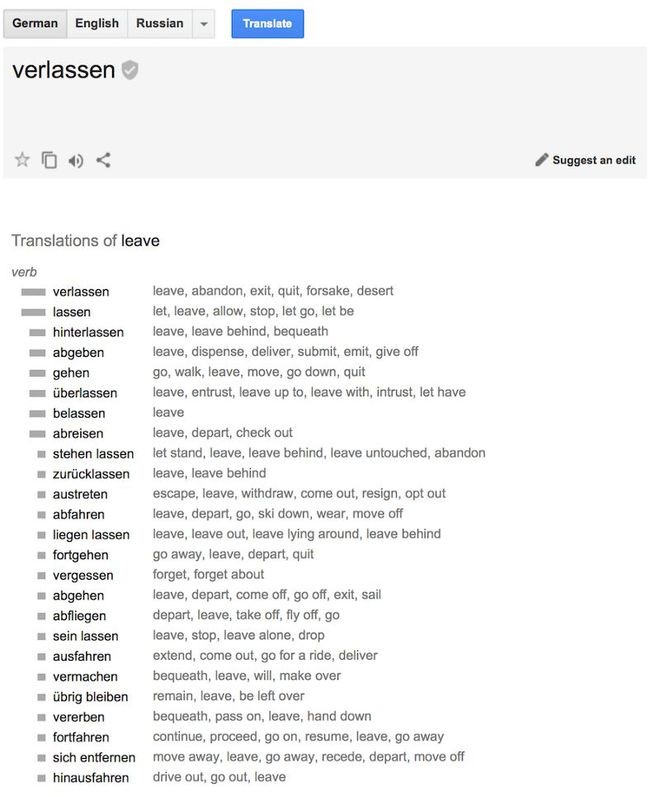
图:Google的统计翻译内幕,会统计概率,也会反向统计
但这个方法还有一个问题:机器如何或什么时候才会将单词“Das Haus”与单词“building”关联到一起?而我们又如何知道这是正确的翻译呢?
答案是我们并不知道。最初,机器假定单词“Das Haus”与翻译后的句子中的其他词的关联性都相同。接下来,当“DasHaus”出现在别的句子里,与“house”一词的关联性就会+1。这就是大学机器学习中的经典任务:“单词对齐算法”。
这种机器需要两种语言提供数百万的句子,以便收集每个单词的相关性统计数据。那我们怎样才能拿到这些数据呢?我们从欧洲国会以及联合国安理会会议(他们提供所有成员国的语言翻译,你可以点击这里下载:https://catalog.ldc.upenn.edu/LDC2013T06,http://www.statmt.org/europarl/)截取了一部分。
基于单词的SMT
最初,第一个统计性翻译系统将句子分割成单词,因为这种方法最直观且最有逻辑性。IBM的首个统计性翻译模型称之为Model 1。听起来很高雅,是不是?猜猜看他们会如何命名第二个系统呢?
Model 1:“词袋”
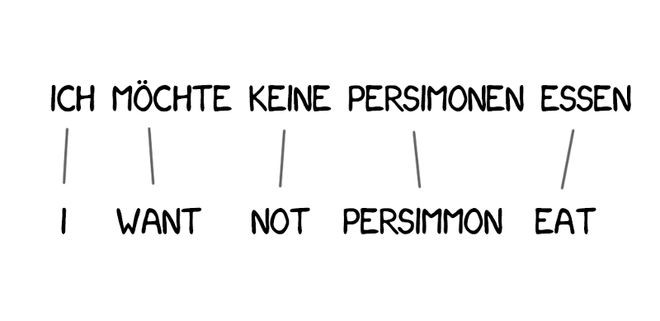
Model 1使用了最经典的方式:将句子分割成单词,然后计数统计。其中并没有考虑单词的顺序。最棘手的问题在于有时可以将多个字(或词)翻译成一个字(或词)。例如,“吃饭”可以翻译成“eat”,但这并不意味着反之亦然(“eat”只能翻译成“吃”)。
点击这里查看用Python实现的几个简单例子:https://github.com/shawa/IBM-Model-1
Model 2:在句子中考虑单词的顺序
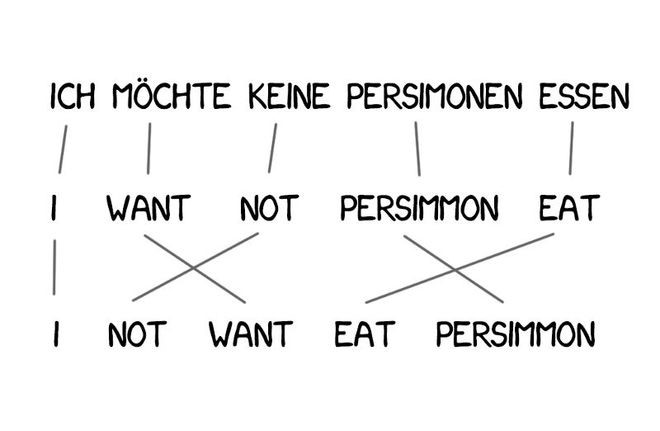
Model 1的问题在于缺乏对单词顺序的理解,并且在有些场合这是十分重要的问题。
Model 2解决了这个问题:它记住了单词在输出句子中通常所处的位置,并在中间步骤重新排列单词,让句子听上去更加自然。情况有所好转,但是最后的翻译结果依然有点蹩脚。
Model 3:额外的处理
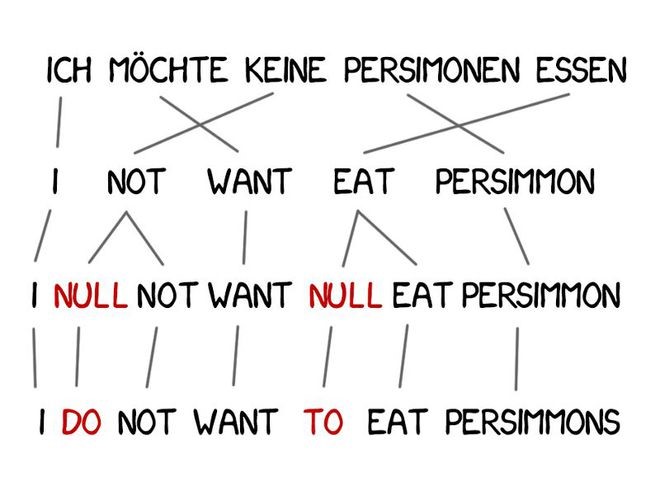
有些单词在翻译中出现得非常频繁,例如德语中的冠词或英语否定句中的“do”。“Ich will keine Persimonen” → “I do notwant Persimmons.” 为了处理这种情况,需要向Model 3中增加额外的两步。
如果机器觉得有必要添加新词的时候,先插入NULL标记。
为每个标记词选择合适的语法助词或单词。
Model4:单词对齐
Model 2也考虑了单词的对齐,但是却不懂得重新排序。举例来说,形容词通常都需要与名词交换位置,并且不管它记住了多好的顺序,都无法改善输出的结果。因此,Model 4引入了被人称之为“相对顺序”的概念,即该模型学习了两个单词是否经常互换位置。
Model5:修正bug
Model 5在功能上没有创新,只是为学习增加了更多参数,并修正了单词位置冲突的问题。
尽管基于单词的系统为机器翻译带来了革命性的创新,但是它们依然无法处理大小写、性别以及同音异意词。每个单词都由机器进行单一的看似正确的方法进行翻译。如今我们已经看不到这样的系统了,他们已经被更先进的基于短语的方法所取代了。
基于短语的SMT
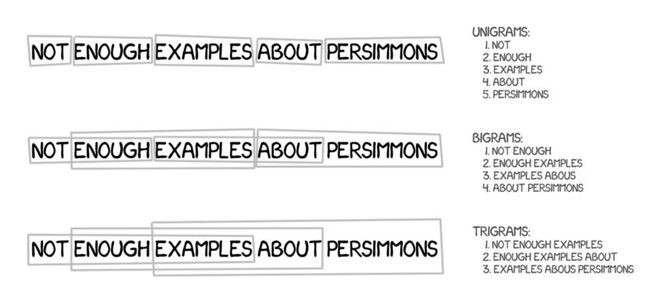
这个方法继承了所有基于单词的翻译原则:统计、重新排序以及词汇的修改。但是,这种方法将文本分解成短语,而非单词。这个方法是源于n元语法,即文本中连续出现的n个语词。
因此,机器学习翻译多个词出现的稳定组合,极大地提高了翻译的精度。
这个方法的难点在于:不是所有的短语都拥有如此简单的语法结构,如果有人懂得语言学以及句子的结构,对其进行干涉,那么翻译的质量会大幅下降。计算机语言学的大师,Frederick Jelinek开玩笑说:“每当我炒掉一个语言学家,演讲翻译机的性能就会有所提升。”
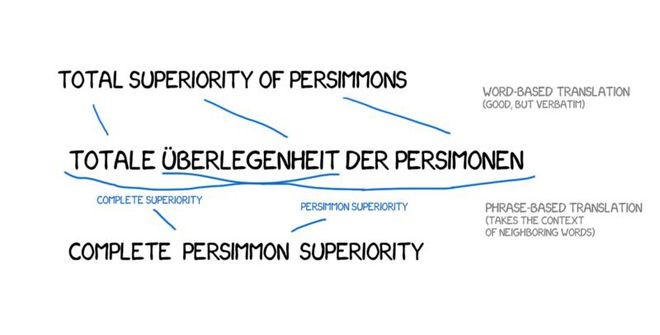
除了精度的提高,这种基于短语的翻译还为双语文本的学习提供了更多方式与途径。对于基于单词的翻译,元文本的精确匹配非常关键,所以任何文学或免费的翻译都被排斥在外。而基于短语的翻译没有这样的问题。为了提高翻译,研究人员甚至为此尝试解析不同的语言新闻网站。
2006年起,所有人都开始用这种方法。截止到2016年,市场上涌现了Google翻译、Yandex(一家俄罗斯互联网企业,旗下的搜索引擎在俄国内拥有逾60%的市场占有率)、Bing(一款由微软公司推出的网络搜索引擎)、以及其他基于短语的高端在线翻译。可能有人记得当时有一段时间,Google的翻译时而呈现完美的句子翻译,时而翻译得狗屁不通。那些完全讲不通的翻译就来自基于短语的翻译。
旧时的基于规则的方法可以稳定地提供可预测却很糟糕的结果。而统计方法令人惊讶却又很神秘莫测。Google翻译毫不犹豫地将“three hundred”翻译成“300”。这就是所谓的统计偏差。
基于短语的翻译变得非常流行,所以现在人们说“统计方式的机器翻译”实际上指的就是基于短语的翻译。直到2016年,所有研究均称赞以基于短语的翻译是最先进的翻译。但是却没人想到Google已经点燃了导火索,准备改变我们对机器翻译的整体理解了。
基于语法的SMT
需要简单介绍下这个方法。在神经网络出现之前的很多年,基于语法的翻译被看作是“机器翻译的未来”,但是这个想法却未能成真。
基于语法的翻译的支持者认为,可以尝试将其与基于规则的方法合并。有必要对句子进行非常精确的语法分析——确定主语、谓语以及其他部分,然后创建句子树形结构。通过这个树形结构,机器可以学习在语言之间进行语法单元的转换,并通过但与或短语翻译其余部分。这将彻底解决单词对齐的问题。
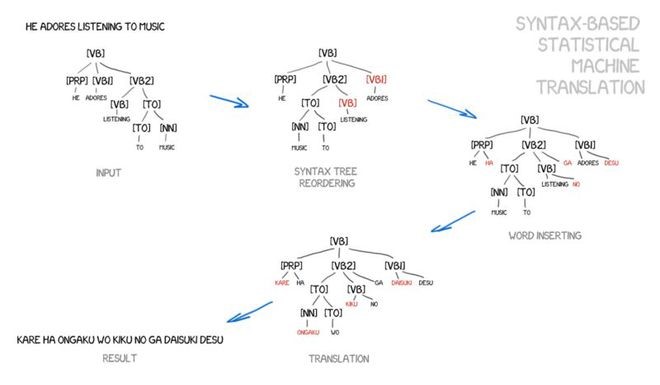
图:从Yamada与Knight的论文及幻灯片中摘取的例子
但是问题在于,语法分析的进行非常糟糕,尽管我们以为它在很早以前就得到了解决(因为我们有很多现成的语言库)。我尝试用语法树来解决比解析主语和谓语更复杂的问题时,每次都以失败告终。
统计机器翻译(Statistical Machine Translation,简称SMT)将机器翻译的研究推进到了一个新的阶段。通过从大规模的真实语料库中获取翻译知识,这种方法极大地改善了获取语言学知识的手段,有效地提高了译文质量。SMT利用平行语料库来训练模型参数,不需要人工编写规则,直接训练平行语料库即可构建机器翻译系统,因此人工成本低,开发周期短。这使得SMT成为谷歌、微软、百度等国内外公司在线机器翻译系统的核心技术。
然而,SMT仍然存在一些问题。尽管它能从真实语料库中获取语言学知识,但仍需依赖人类专家设计特征来表示各种翻译知识源。由于不同语言之间的结构转换非常复杂,人工设计的特征难以覆盖所有的语言现象。此外,SMT对语料库的依赖性很强,难以引入复杂的语言知识,即使使用大规模语料库训练数据,仍然面临严重的数据稀疏问题。因此,统计机器翻译技术仍需进一步改进。